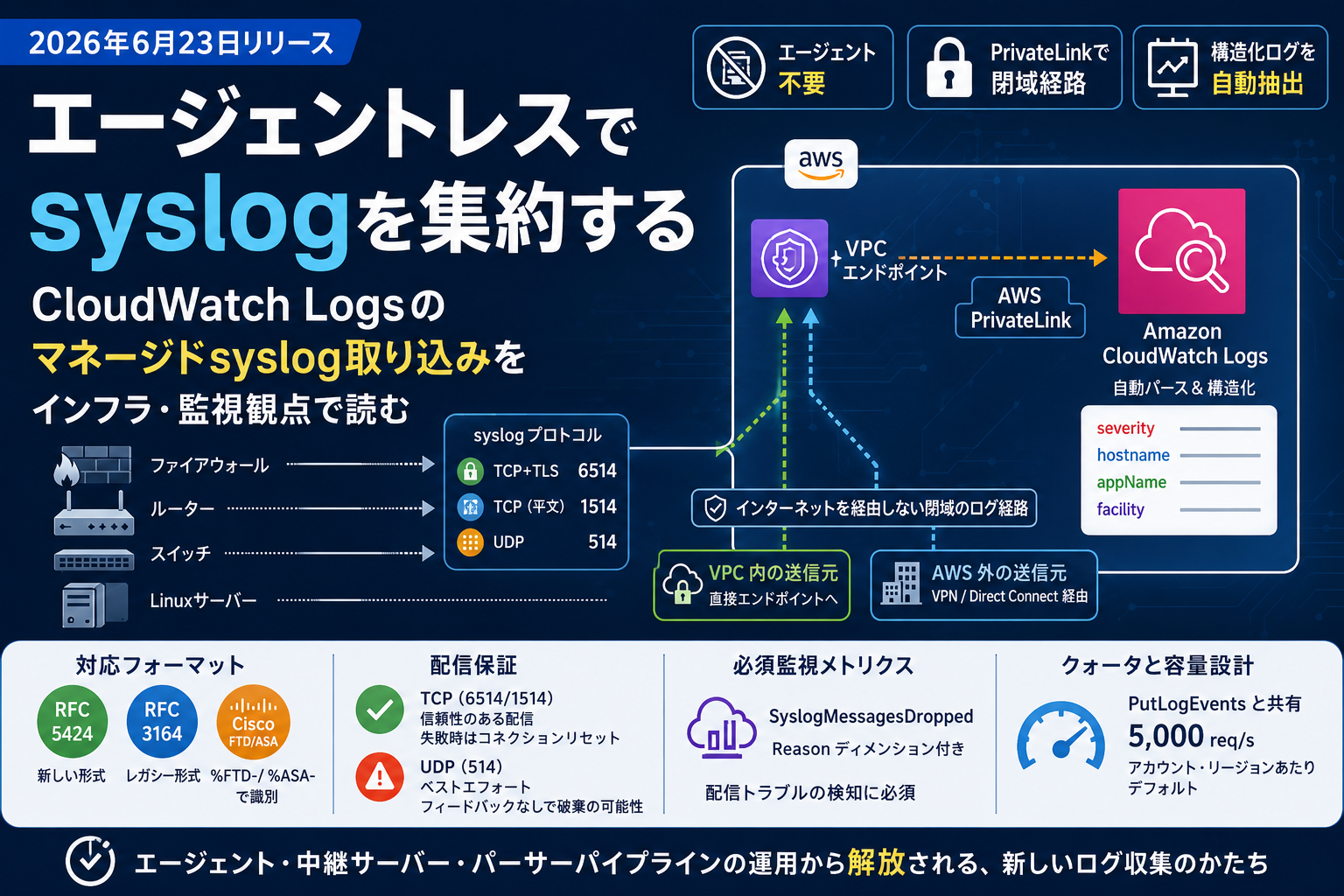
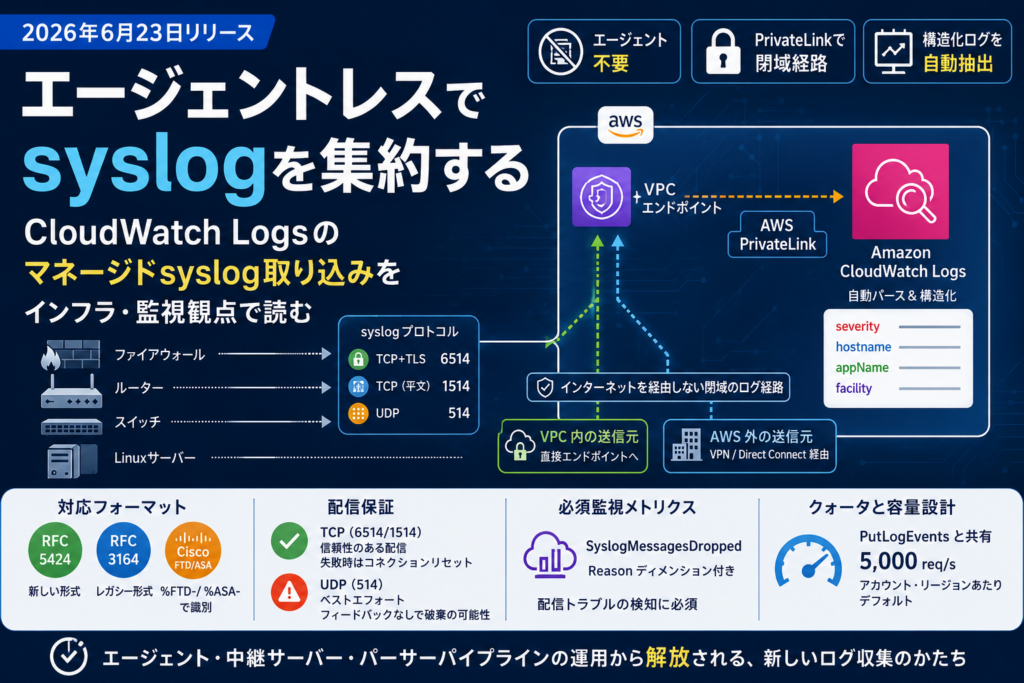
2026年6月23日、Amazon CloudWatch Logs が マネージドsyslog取り込み(managed syslog ingestion) に対応した。ファイアウォール、ルーター、スイッチ、Linuxサーバーといったネットワーク機器・サーバーからのsyslogを、エージェントを一切導入・管理せずにCloudWatch Logsへ直接送り込めるようになった機能だ。
地味な発表に見えるかもしれないが、分散環境のログ収集基盤を運用してきた立場からすると、設計の選択肢を大きく変える内容を含んでいる。本記事ではインフラ構成と監視運用の観点から、この機能の中身を掘り下げる。
何が嬉しいのか ― 「エージェントの群れ」からの解放
これまでネットワーク機器のsyslogをCloudWatchに集約しようとすると、間に何らかの中継役を立てるのが定石だった。rsyslog/Fluentdを載せた収集用サーバーを用意してCloudWatch Agentで転送する、あるいはLambda経由でPutLogEventsを叩く、といった構成だ。
この「中継役」が運用の重荷になる。台数が増えればパッチ適用・バージョン管理・冗長化・スケーリングがすべて自分の責任範囲になり、収集基盤そのものを監視する必要まで出てくる。ログを集めるための仕組みが、新たな監視対象を生むという本末転倒が起きやすい。
今回のマネージドsyslog取り込みは、この中継層をAWS側のマネージドサービスに置き換える。送信元の機器が標準のsyslogプロトコルでVPCエンドポイントに向けて喋るだけで、あとはAWSがパース・配信まで面倒を見る。エージェントもパーサーパイプラインも、運用者の手元から消える。
アーキテクチャ ― PrivateLinkで閉じたログ経路
構成の要点はシンプルだ。送信元はTCP、TCP+TLS、UDPのいずれかで、自アカウント内のVPCエンドポイントにsyslogを送る。トラフィックはそこから AWS PrivateLink経由でCloudWatch Logsのsyslogサービスへトンネリング され、パブリックインターネットを一切経由しない。ログという機微なデータの経路がネットワーク的に隔離される点は、コンプライアンス要件を抱える環境では効いてくる。
送信元の位置によって到達経路が変わる。
- VPC内の送信元:VPCエンドポイントへ直接送信できる。
- AWS外の送信元(オンプレのデータセンター、支社、コロケーション施設など):既存のVPN接続またはDirect Connect経由でVPCエンドポイントに到達する。
つまりオンプレのファイアウォールやスイッチであっても、すでにVPN/Direct Connectでハイブリッド接続が組まれていれば、その経路に相乗りしてログを送れる。新たに専用線やパブリック経路を引く必要はない。
プロトコルとポート ― TCP+TLSを基本線に
サポートされるトランスポートは3種類。設計時にどれを選ぶかで信頼性と運用が変わる。
| プロトコル | ポート | 性質 |
|---|---|---|
| TCP + TLS | 6514 | 転送中の暗号化あり。コンプライアンス要件がある場合の推奨 |
| TCP(平文) | 1514 | 平文だがPrivateLinkでネットワーク隔離済み |
| UDP | 514 | ベストエフォート配信 |
TLS(6514)の終端はネットワークロードバランサー側で行われ、Amazon Trust Servicesが発行するAWSマネージド証明書が使われる。送信元クライアントは特別な設定なしでこの証明書を信頼できるため、証明書の配布・更新といった運用が発生しない点は地味にありがたい。
設計の基本線としては、要件が許す限りTCP+TLS(6514)を選びたい。平文TCP(1514)はPrivateLinkで経路が隔離されているとはいえ、暗号化の有無は監査の観点で問われやすい。UDP(514)は後述の通り配信保証がないため、欠落が許される用途に限るべきだ。
対応フォーマットと自動フィールド抽出 ― パーサーを書かなくていい
CloudWatch Logsは受信したsyslogのフォーマットを 自動判別してパース し、構造化フィールドを抽出する。対応フォーマットは3つ。
- RFC 5424(新しい形式):構造化データ、ISO 8601タイムスタンプ、アプリ名・プロセスIDの明示フィールドを持つ。
- RFC 3164(BSD syslog、レガシー形式):BSD形式タイムスタンプとTAGフィールド。ファイアウォール・ルーター・スイッチなど多くのネットワーク機器が今も使う。
- Cisco FTD/ASA:Cisco Firepower Threat Defense / Adaptive Security Applianceの形式。メッセージ本文の
%FTD-/%ASA-タグで識別される。
ここがインフラ運用上の本丸だ。従来は機器ごとに異なるsyslog方言を吸収するために、自前のパースパイプライン(正規表現の山)を組んで保守し続ける必要があった。それが不要になる。
メッセージは元の生フォーマットのままロググループに保存されつつ、facility、severity、hostname、appName といった構造化フィールドが抽出され、CloudWatch Logs Insightsでクエリできる。たとえばファイアウォールのsyslogを取り込んで、severity や hostname で即座に絞り込み、セキュリティイベントの調査や接続トラブルの切り分けに使う、といった流れがそのまま実現する。
RFC 5424であれば facilityCode(0–23)、severityCode(0–7)、procId、msgId、structuredData まで分解される。Cisco FTD/ASAでは deviceId、messageId(106023 のようなCiscoメッセージ番号)、subsystem まで抽出されるため、特定のメッセージIDでのフィルタリングがそのまま効く。
監視観点 ― 配信保証とSyslogMessagesDroppedの監視が肝
ここからが運用設計で最も注意すべきポイントだ。syslogはHTTPベースの取り込みと違い、1メッセージごとの成功応答を送信側に返さない。サービスが受け取ったメッセージはバッファされ、一時的なエラーにはリトライしつつロググループへ配信される。配信保証はトランスポートの選択に依存する。
TCP(6514 / 1514)の挙動
通常運用下では信頼性のある配信を提供する。配信できない状況では サービス側がTCPコネクションをリセット して送信元に失敗を通知する。コネクション中のメッセージは落ちる可能性があるが、リセットによる即時のバックプレッシャーが返るため、クライアント側は異常を検知してローカルにバッファできる。キャパシティ逼迫時には新規TCPコネクションを早期に拒否し、同じくバックプレッシャーを与える。
コネクションリセットが起きる条件は明示されている。
- VPCエンドポイントポリシーがアクセスを拒否している
- アカウントの
PutLogEventsクォータを超過している - 宛先のロググループが存在しない
- ロググループのリソースポリシーがアクセスを拒否している
これらは設定ミスや権限不備で起こりやすい類のものだ。送信側でコネクションリセットを検知・アラートできるよう、ネットワーク機器やrsyslog側のバッファ・再送設定を併せて見ておきたい。
UDP(514)の挙動
ベストエフォート。配信できないメッセージは 送信側へのフィードバックなしに破棄 される。ネットワーク輻輳やキャパシティ制約でも失われうる。欠落が許容できない用途では使うべきでない。
必須の監視メトリクス:SyslogMessagesDropped
配信トラブルを検知・対応するために、CloudWatchの SyslogMessagesDropped メトリクスを監視する ことが事実上必須になる。このメトリクスには Reason ディメンションが付き、なぜ破棄されたのか(クォータ超過なのか、権限なのか等)が分かる。
監視設計としては、SyslogMessagesDropped にしきい値アラームを設定し、Reason で原因を切り分けられるようにしておくのが定石になるだろう。syslogは応答が返らない以上、「届いているつもりで実は落ちていた」というサイレント障害が起きやすい。このメトリクスを見ない運用は、目隠しでログを送っているに等しい。
クォータと容量設計 ― PutLogEventsを食い合う点に注意
見落としやすいのがスループットの制約だ。
| 制限 | 値 | 補足 |
|---|---|---|
| 最大メッセージサイズ(TCP) | 64 KB | 標準的なsyslogは通常これを大きく下回る |
| 最大メッセージサイズ(UDP) | 8 KB | 同上 |
| 取り込みスループット | PutLogEvents と共有 | アカウント・リージョンあたりデフォルト5,000リクエスト/秒 |
注目すべきは、syslog取り込みのスループットがアカウントの PutLogEvents クォータを消費する 点だ。既存のアプリケーションログやCloudWatch Agentからの送信と同じ枠を食い合う。大量のネットワーク機器からsyslogを集約する場合、既存のログ取り込みと合算でクォータに当たる可能性がある。
容量設計の段階で、対象機器の総syslogレートを見積もり、既存のPutLogEvents消費量と合わせて余裕があるか確認しておきたい。不足するなら、Service Quotas経由でPutLogEventsの引き上げを申請できる(このクォータは調整可能)。
提供リージョン
全商用AWSリージョンで利用可能。ただし中東(UAE)、中東(バーレーン)、イスラエル(テルアビブ)は除く。東京・大阪リージョンは対象に含まれる。
まとめ ― 収集基盤を「持たない」という選択肢
この機能が変えるのは、ログ収集アーキテクチャにおける責任分界点だ。これまで自前で抱えていた中継サーバー・エージェント・パーサーパイプラインという3つの運用負荷を、まとめてマネージド側に寄せられる。
インフラ観点での導入判断のポイントを整理すると、次のようになる。
- 経路:オンプレ機器は既存のVPN/Direct Connectに相乗りでき、新規のパブリック経路は不要。PrivateLinkでインターネットを経由しない。
- プロトコル選定:基本はTCP+TLS(6514)。証明書はAWSマネージドで運用不要。UDPは欠落許容用途に限定。
- 監視設計:
SyslogMessagesDropped(Reasonディメンション付き)の監視は必須。syslogは応答が返らずサイレント障害になりやすい。 - 容量設計:取り込みスループットは
PutLogEventsクォータ(5,000 req/s)を既存ログと共有。事前の見積もりと、必要ならクォータ引き上げを。
「ログを集めるための仕組みを運用する」という長年の課題に対して、マネージドサービスで応える正攻法の一手だ。分散環境のログ可視性を一元化したいが収集基盤の保守コストに悩んでいる、という現場ほど検討の価値がある。
出典:AWS What’s New「Amazon CloudWatch Logs supports managed syslog ingestion」(2026年6月23日)、および Amazon CloudWatch Logs ユーザーガイド「Syslog ingestion」



